|
|
|
|
 |
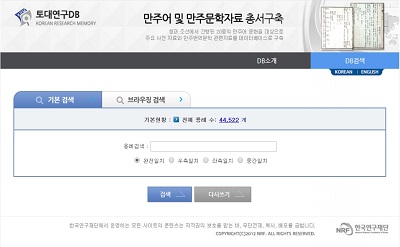
데이터베이스 소개 |
|
본 연구는 만주어문학의 통합적연 연구를 위한 만주어 사전 및 만주문학 자료 DB 구축 (Building of Manchu Dictionary and Literature DB for Integral Study of Manchu Language and Literatures)라는 제목으로 2012년 9월 1일부터 3년 간 진행된 과제의 결과물이다. 이 연구의 목적은 청과 조선에서 간행된 20종의 만주어 문헌을 대상으로 하여 주요 사전 자료와 만주번역문학 관련 텍스트 자료를 입력하고 그 결과를 데이터베이스로 구축하는 것이다.
입력 단계에서는 자료의 구조를 반영하는 특정한 표지를 붙이고 주석을 추가하였다. 만주어 어휘 자료를 전산화하여 통합적인 사전 DB를 구축하였고, 텍스트 자료를 滿漢, 滿韓 병렬 말뭉치로 구축하고 어휘색인 DB를 구축하였다. 최종 입력 결과물은 웹 검색 서비스가 가능하도록 관계형 데이터베이스 형태로 변환하였다.
|
|
|
기대효과/활용방안 |
|
이 연구는 그 입력 대상 자료만 하더라도 전 세계의 도서관에 소장되어 있기 때문에, 그 자료들을 한국에서 모으려면 엄청난 시간과 노력이 소요된다. 따라서 지금까지는 이런 시도를 할 엄두를 쉽게 내지 못하였다. 일본학자들이 유일하게 이런 방면으로 조금씩 관심을 보여 왔지만 본격적으로 이루어지지는 못하고 있다. 이처럼 쉽게 구하기 힘든 만주어 자료들을 수집하고 정리하여 후속 연구를 위한 큰 틀을 마련한다는 점에서 이 연구는 매우 중요한 학술적 가치를 지닌다.
우선 이 연구는 만문 문헌을 해독하는 기초가 될 것이다. 만문 문헌을 해독하려면 무엇보다도 어휘의 의미를 파악하는 것이 중요하다. 만주어는 문법이 북부 퉁구스어군이나 동남부 퉁구스어군처럼 복잡하지 않기 때문이다. 지금까지 많은 만주어 사전들이 편찬되었지만, 그 사전들은 대부분 ≪御製增訂淸文鑑≫을 비롯한 극히 일부의 어휘 자료를 번역한 것이다. 그러나 이 연구에서 입력하려고 하는 어휘 자료는 모두 11종 159권 146책에 달하여, 지금 보존되어 있는 만주어 자료를 해독하는 데 필요한 어휘를 모두 망라할 수 있을 것이다.
이 연구에서 입력하는 자료들은 단순히 어휘 자료에 그치지 않고 텍스트 자료도 입력함으로써 당대 만주 및 중국의 문학, 역사, 사회 등 분야의 연구에 필요한 자료를 제공하게 될 것이다.
이 연구에서는 현전하는 주요 만문 서적의 자료를 수집하고 입력하여 데이터베이스 형식으로 가공된 결과물을 전 세계의 사용자들이 편리하게 이용할 수 있게 되었다. 이 연구를 통해서 한국이 세계 만주어 연구의 중심이 될 것으로 기대되며, 이 연구는 IT 기술과 자료의 가공 및 개방이라는 최신 패러다임을 통해 세계 학계에 기여한다는 점에서 한국 학계의 위상을 높였다.
본 연구에서 대상으로 삼은 자료의 대부분은 만주어와 한어(漢語)가 나란히 제시되는 만한합벽의 형식으로 되어 있다. 이처럼 만한합벽의 형식으로 제시되는 자료는 만주어 연구는 물론 중국어문 연구에 매우 중요한 자료이지만, 그간 중국어문학 등 관련 학문 연구자들은 이 자료들을 제대로 활용하지 못하였다. 이제 이 연구를 통해 구축한 만한합벽 자료의 데이터베이스를 이용하여 이러한 한계를 극복할 수 있게 되었다.
만주퉁구스 어파에 속하는 만주어 자료의 깊은 연구를 통하여 알타이어학 연구에도 기여할 것이다. 한국어는 “알타이어족”에 속할 가능성이 크므로, 본 연구의 결과물은 한국어의 계통 연구를 위한 기반을 마련한다고도 할 수 있다.
마지막으로 연구 기간 동안 정기적인 만주어 연구 집회를 열어서 공동 연구원들의 만주어 실력을 끌어올림과 동시에 연구 보조원들의 만주어 실력을 배양함으로써 만주어를 전공하는 학문 후속 세대를 배출하였다.
|
|
|
사업명 : 인문사회연구분야 토대기초연구지원 |
|
연구과제명 : 만주어 및 만주문학자료 총서구축
[기초학문자료센터(KRM)과제 정보
]
연구책임자 : 남승호
연구수행기관 : 서울대학교
연구기간 : 3 년 (2012년 09월 01일 ~ 2015년 08월 31일)
|
|
|
|
|
|
|
|